2026 年一开年,DeepSeek 就用一篇 mHC 论文 [1] 吸引了众多的关注。在深度学习架构设计中,残差连接一直是支撑深层网络训练的核心。在更早一些的时候,由 [2] 提出的超连接(Hyper-Connections,HC)通过拓宽残差流并引入可学习的多路径连接,显著提升了传统残差网络的模型性能。但 mHC 的论文指出,HC 中由于残差映射矩阵不受限制,因此也带来了训练不稳定的问题。为了解决这一问题,Manifold-Constrained Hyper-Connections(mHC)应运而生,它通过将残差映射矩阵约束为双随机矩阵(即行和与列和均为 1 的非负取值矩阵),将信号的大小进行了限制,从而保证了大规模训练的稳定性。
施加这个约束在数学上等价于将一个矩阵投影到Birkhoff 多面体上,其中 Birkhoff 多面体 Bn 即为所有 n×n 的双随机矩阵构成的集合。在 mHC 中,作者使用了Sinkhorn-Knopp 算法进行迭代计算。在实际训练中,每一层、每一个 token 都需要执行这样的投影,因此其计算效率将影响到整体的训练成本。Sinkhorn-Knopp 是一个非常经典的算法,被广泛用于双随机矩阵的生成。然而,其收敛速度在很多情况下却比较缓慢,尤其是当输入矩阵元素的幅度较大时。因此,使用固定且较少次数的迭代(如 mHC 论文中使用的 20 次)可能无法给出足够精确的双随机矩阵,进而削弱 mHC 的稳定性保证。
针对这一问题,本文提供了一种改进 mHC 实现的思路,为 mHC 中常见的 4×4 Birkhoff 投影设计了一套加速方案。在本文中我们通过融合最优传输方法、牛顿法、隐式微分和寄存器级别的 CUDA 算子优化,提出了一种精度和速度都显著超越现有 Sinkhorn-Knopp 方法的高效实现。
1. 背景:mHC 与 Birkhoff 投影
mHC 的一项核心创新在于对残差混合矩阵施加双随机约束。具体而言,给定一个学习得到的取值为正的矩阵 ,我们需要将其投影到 Birkhoff 多面体 上(在 Kullback-Leibler 散度的意义下):
其中 Kullback-Leibler (KL) 散度的定义为
为了保证 取值为正,我们通常会做一次指数变换,,其中 是一个无约束的矩阵,此处的 指的是逐元素的指数运算。因此,Birkhoff 投影问题的核心是如何给定矩阵 来计算 。
而非常值得注意的是,优化问题 (1) 与熵正则化的最优传输 (OT) 问题是等价的。熵正则 OT 是近几年统计学习领域的热门主题,有非常多的文献对其进行了探讨,因此也积累了一系列的求解思路和工具。熵正则 OT 要解决的是如下的最优化问题:
其中 是一个给定的 成本矩阵, 和 是两个非负向量,且 (在一般的定义中该求和为 1,但我们此处可以对其进行放松), 是熵函数项, 是正则化参数,约束 的定义为
可以证明,当 ,, 及 时, 就等于熵正则 OT 的最优解,此时 正是 Birkhoff 多面体 。因此,如果我们有求解熵正则 OT 的高效算法,那么 Birkhoff 投影也就可以当作是一个特例得以解决了。
事实上,求解熵正则 OT 的一个经典方法正是 Sinkhorn-Knopp 算法,它通过反复归一化矩阵的行和列来逼近最优解,迭代格式非常简单:
其中 , 表示向量逐元素相除。
然而,Sinkhorn-Knopp 算法的收敛速度对 的动态范围较为敏感。当 取值较小,或 元素的绝对值较大时,算法的收敛速度往往会显著变慢,需要很多次迭代才能让行和与列和接近 1。
2. 解决思路:牛顿法求解对偶问题
熵正则化 OT 的原问题 (2) 是一个有约束的最优化问题,但其对偶问题却具有一些特殊的性质,其形式如下:
观察这一对偶形式,可以发现它其实对应一个 无约束凸优化问题,且变量个数 远小于原问题的 。对偶问题 (3) 与原问题 (2) 具有紧密的联系:如果我们能获得对偶问题的一组最优解 ,那么 (2) 的最优解就可以表达为
接下来我们将看到,对于 的 Birkhoff 投影问题,我们可以将对偶变量化简为 3 维,从而能够应用 牛顿法 来进行高效的求解。
2.1 对偶问题的降维
我们首先注意到,对偶问题 (3) 中 对于 有一个冗余的自由度:对于任意的 , 和 都将给出相同的 函数值。因此,我们可以始终固定 ,而只去优化其他对偶变量的取值。
而熵正则化 OT 的另一条重要性质在于,给定 取值时,最优的 具有显式解:
其中 ,而 代表 的第 个元素。由此可以发现,在对偶问题 (3) 中,看上去我们需要优化 个变量,但实际上只需要找到最优的 ,即 的前 个元素,然后设定 以及 即可得到整体的最优对偶变量。因此,对偶问题 (3) 实际上的自由变量仅为 个。
对于 的 Birkhoff 投影问题来说,这意味着我们只需要求解一个 3 维的凸优化问题即可,这就给了我们巨大的自由度去探索不同方法的性能。
2.2 牛顿法
回到 的 Birkhoff 投影问题 (1),由于它可以被转化为熵正则 OT 的一个特例,因此我们可以定义 3 维的自由变量 ,进而求解凸优化问题
其中 。这里我们对 函数取了负号,从而把对偶问题 (3) 的凹函数最大化转成了凸函数的最小化问题。
对于光滑、无约束的凸优化问题而言,有非常多的优化方法可以用来寻找函数的最小值,例如属于一阶方法的梯度下降法,以及属于二阶方法的牛顿法等。而已有的优化理论表明,牛顿法具有局部二次的收敛速度,是收敛非常快速的经典方法,在实际使用中往往只需要几次到几十次迭代就能获得高精度的解。牛顿法的更新公式为:
其中 和 分别是目标函数 的梯度和 Hessian 矩阵, 是第 次迭代中使用的步长,通常通过线搜索方法确定。
经过一系列的推导,我们可以得到梯度的显式表达式:
基于上述计算过程中得到的 和 , 的 Hessian 矩阵也有简洁的表达式:
其中 表示 的前三列构成的子矩阵。
有了梯度和 Hessian 矩阵,我们就可以进行牛顿更新,而 可以通过线搜索方法确定。在本文的实现中,我们采用了一种简化的方法:依次尝试步长 1.0,0.5,0.1,0.05,0.01,如果某个步长下的新迭代点的目标函数值和梯度小于当前的迭代点,就接受该步长,并更新 至 。如果所有的尝试点都不满足条件,则利用一次 Sinkhorn-Knopp 迭代作为备用方案。牛顿法具有二次收敛速度,通常只需少数几步即可达到较高的精度。
需要特别强调的是,此处之所以适合采用牛顿法,是因为 Hessian 矩阵的大小仅为 ,对它求逆可以直接写出解析式,计算量极小。在大规模的熵正则 OT 问题中(例如 为上千至上万),一般的牛顿法就不再适用了,而需要采用特殊的设计。这里顺便给自己打个广告,推广一下之前的两项工作 [3] 和 [4],它们利用稀疏化的牛顿方法给出了大规模熵正则 OT 的高效求解算法,代码开源在 https://github.com/yixuan/regot-python。另外一篇综述文章 [5] 则系统介绍了稀疏化方法在大规模 OT 问题中的应用。
3. 避免循环:基于隐式微分的反向传播
为了将投影算子嵌入端到端的模型训练,我们还需要对投影算子求导,以便将梯度传递给输入矩阵 。传统的做法是展开 Sinkhorn-Knopp 迭代循环,记录中间变量,然后对其中的每一步行列归一化进行反向传播——这一过程既占用内存,又消耗计算时间,而且数值上可能还不稳定。
回顾投影的过程,它本质上是将一个矩阵 映射成 。假设在后续计算中,某个损失函数 对算子输出 的导数是 :
那么根据求导的链式法则,我们有
其中 是优化问题 (4) 的最优解,显然它隐含地是 的函数。
在 (5) 式的各项中,由于我们已经有 (注意 就是 ),因此 和 都容易推导出来,问题的核心在于计算 。
由于 是通过优化算法计算出来的,并没有解析表达式,因此计算 就需要用到隐函数定理:最优解 满足 ,将该等式视为关于 和 的隐函数,那么 对 的导数就是
经过一些繁琐的推导,针对 的情形,我们可以得出如下的计算公式:
其中 表示 的单位阵, 表示矩阵的逐元素乘法。
这一串表达式看上去非常复杂,但实际上仅由 和上游梯度 计算得到,完全不需要存储 Sinkhorn-Knopp 迭代过程,内存占用极小。涉及的计算也都是 或 的矩阵-向量运算,因此反向传播的计算量也非常低。
4. GPU 实现:在寄存器中处理 矩阵
实际模型训练中,我们往往需要同时处理大量(例如批次大小从几千到几十万)的 矩阵。每个矩阵的投影相互独立,非常适合并行计算。针对上一节提出的牛顿法,我们利用了 CUDA 线程束(Warp)级编程,让一个 Warp(32 个线程)同时处理两个矩阵,并且所有数据交换均在寄存器内完成,核心算法完全避免访问共享内存或全局内存。
4.1 线程布局
我们将一个 Warp 中的 32 个线程分为两组:编号 0-15 处理第一个矩阵,编号 16-31 处理第二个矩阵。每个矩阵的 16 个元素按行分布在对应的 16 个线程中(假设重新编号为 0-15),其中编号为 id 的线程对应矩阵元素(row,col),其中 row = id // 4,col = id % 4。线程的布局可以参考下图:

.2 并行魔法
在 GPU 上编程的思路会和在 CPU 上有很大的不同,往往需要以“SIMT(单条指令、多个线程)”为原则设计算法。以计算 (列和)为例,每个线程持有自己的 ,但我们希望每个线程最终得到所在列的列和,这就需要在不同矩阵行的线程之间进行通信。解决这一问题最简单的办法是利用全局内存,让不同的线程对同一段内存地址进行读写,从而交换数据。然而,读写内存是相对耗时的操作,更好的办法是让计算都发生在寄存器中。幸运的是,CUDA 编程支持两条特殊的指令,利用它们可以高效地对 矩阵进行各种并行的运算:
• _shfl_xor_sync(mask, val, 4):交换同一 Warp 中相隔 4 个线程的值,对应到矩阵元素,即交换 (i, j) 与 (i+1, j) 的取值(因为行索引差 1,对应线程差 4)。• _shfl_xor_sync(mask, val, 8):交换同一 Warp 中相隔 8 个线程的值。
组合使用上面两条指令,再经过两次并行加法运算,就可以让每个线程得到对应矩阵列的列和。这个过程用文字解释起来比较费力,但用下面的流程图就非常容易理解:
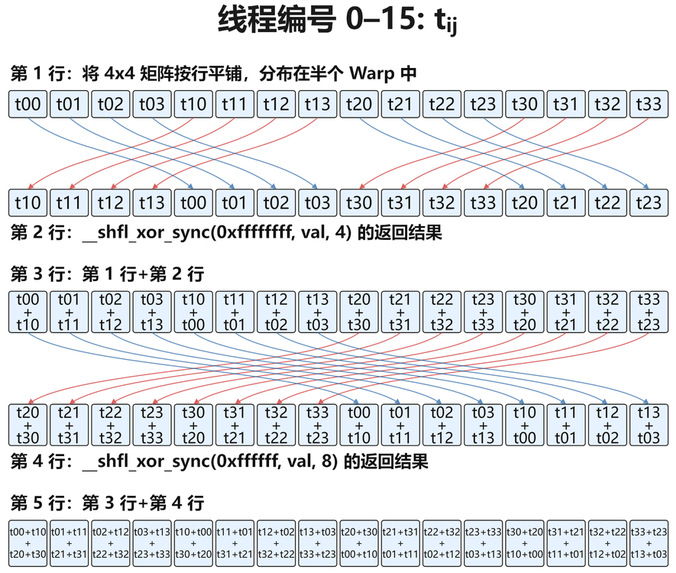
可以看出,整个过程仅用了 4 条指令,且全部在寄存器完成,没有内存访问的开销。
类似地,我们接着实现了行求和、内积计算、Hessian 构建、牛顿方向求解等所有操作,全部基于寄存器级通信,使得最终的 CUDA 核心在批量处理时表现出非常高的吞吐量。完整的代码开源在 https://github.com/yixuan/mHC-proj。
5. 数值实验
由于目前 DeepSeek 还没有公开他们的 mHC 实现,因此我们先在下面四个开源实现上进行测试。
1. Vanilla:纯 PyTorch 实现的 Sinkhorn-Knopp 算法,使用 20 次迭代; 2. Triton-Sinkhorn:基于 OpenAI Triton 的 Sinkhorn-Knopp 融合算子实现,使用 20 次迭代 (https://github.com/LottoLottoLotto/triton-sinkhorn); 3. mHC.cu:非官方的 mHC CUDA 实现,使用 20 次 Sinkhorn-Knopp 迭代 (https://github.com/AndreSlavescu/mHC.cu); 4. mHC-proj(本文方法):本文提出的牛顿法求解器 (https://github.com/yixuan/mHC-proj)。
5.1 精度对比
我们随机生成 个 矩阵,构成一个 的张量,然后将其作为四种投影实现的输入。我们计算了这 个投影后矩阵的计算误差,其定义为矩阵行和与列和对 1 的误差之和(即 L1 距离),用来衡量输出结果与双随机矩阵的差距。汇总结果如下表:
当输入矩阵的取值范围较小时,例如元素服从 分布,所有方法的均值误差和中位误差都较小。然而,在最差情形下,基于 Sinkhorn-Knopp 迭代的三种方法都给出了远大于中位误差数量级的最大误差。与之对应的是,本文所使用的牛顿法很好地控制了全局的误差,最大值也控制在 数量级。
当输入矩阵的元素取值幅度较大时(如 分布),下表的结果显示,20 次 Sinkhorn-Knopp 迭代的误差很大,最大误差甚至超过 4.0,而本文方法的中位误差仅在 数量级,远小于其他方法,即使是全局最大误差也控制在 0.1 以内。这说明牛顿法能够更好地满足双随机约束,而 Sinkhorn-Knopp 的固定迭代次数可能严重不足。
5.2 速度对比
我们继续说明,上一节中 mHC-proj 所取得的精度优势并未以牺牲计算效率作为代价。我们固定输入分布为 ,然后测试了不同批次大小 下各个方法的前向传播运行时间,并以 mHC-proj 为基准归一化。我们选取 100 次测量的中位数作为汇总指标,总结如下:
由此可见,除了本文的 mHC-proj,其他三个开源实现中,mHC.cu 的计算效率是最高的,但其代价就是在上一节的误差分析中,mHC.cu 在 的输入分布下给出了最大的误差,这说明它是一种不稳定的实现。而基于牛顿法的 mHC-proj 在比其他方法计算更快的前提下,还有着显著更小的计算误差。
如果同时包含正向和反向传播,则 mHC-proj 的优势会更加明显,如下所示:
可见,在 128K 的批次大小下,本文的方法比 mHC.cu 快了 20 倍以上,同时还让投影运算的中位误差缩小了超过三个数量级。
6. 总结与展望
mHC 通过 Birkhoff 投影保证了训练的稳定性,但投影运算本身也带来了计算成本。本文提出的加速方案充分利用了 小矩阵的结构:
• 将对偶问题降维至 3 维,使用牛顿法获得二次收敛速度; • 用隐式微分替代循环展开,高效计算反向传播梯度; • 基于 CUDA Warp 级编程实现极致并行,全部核心计算在寄存器内完成。
实验表明,该方法不仅精度远超固定迭代次数的 Sinkhorn-Knopp 方法,而且速度更快,尤其适合大规模训练场景。对于深度学习架构设计而言,让施加约束的成本最小化,是使其真正实现可扩展的关键,希望这项工作能为 mHC 在大模型上的应用提供一种可行的思路。
参考文献
[1] Xie, Z., Wei, Y., Cao, H., Zhao, C., Deng, C., Li, J., ... & Liang, W. (2025). mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880.
[2] Zhu, D., Huang, H., Huang, Z., Zeng, Y., Mao, Y., Wu, B., ... & Zhou, X. (2025). Hyper-Connections. In The Thirteenth International Conference on Learning Representations.
[3] Tang, Z. & Qiu, Y. (2024). Safe and Sparse Newton Method for Entropic-Regularized Optimal Transport. Advances in Neural Information Processing Systems.
[4] Wang, C. & Qiu, Y. (2025). The Sparse-Plus-Low-Rank Quasi-Newton Method for Entropic-Regularized Optimal Transport. In Forty-second International Conference on Machine Learning.
[5] Ouyang, X., Zheng, H., Liang, H., Zhang, J., Qiu, Y., Meng, C., & Li, M. (2026). Sparsification Techniques for Large‐Scale Optimal Transport Problems. Wiley Interdisciplinary Reviews: Computational Statistics.
作者简介
邱怡轩,上海财经大学统计与数据科学学院副教授,博士毕业于普渡大学统计系,毕业后曾于卡内基梅隆大学担任博士后研究员。主要研究方向包括深度学习、生成式人工智能和大规模统计计算与优化等,科研成果发表在统计学国际权威期刊及机器学习顶级会议上。长期参与建设统计学与数据科学社区“统计之都”,是众多开源软件(如Spectra/RSpectra、LBFGS++、ReHLine、showtext、prettydoc 等)的开发者与维护者。

